仕事でサウンドの波形データから音量(dB)を取り出す必要があったので調べてみました
なお動作確認はWindowsで行いました
目次
Audacityでサウンドデータの音量を書き出す方法
Audacityのインストール
Audacityとはサウンドデータを編集できるツールです。
公式ページからダウンロードしてインストールします
音量を書き出す方法
例えば以下の音声データ「Powerup.wav」をAudacityで開いてみます。
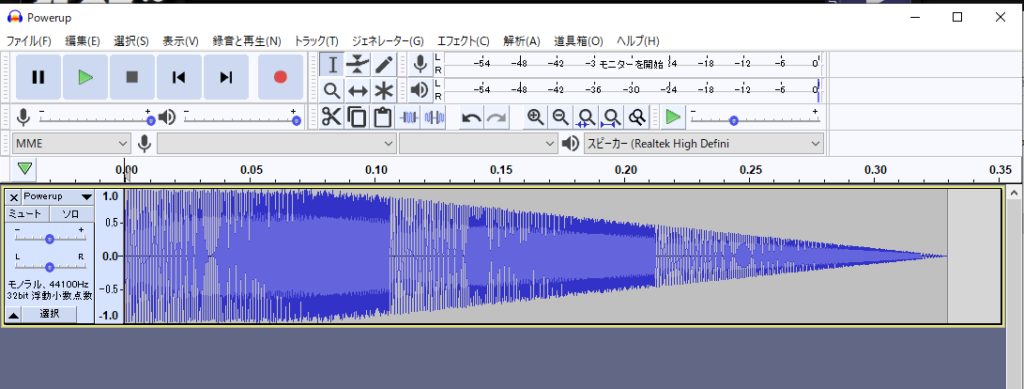
波形データはこのようになっており、0.33秒のデータであることがわかります。
次にメニューから「選択 > すべて」を選んで波形を全選択します。

このように波形の背景色が明るくなれば選択状態となります。
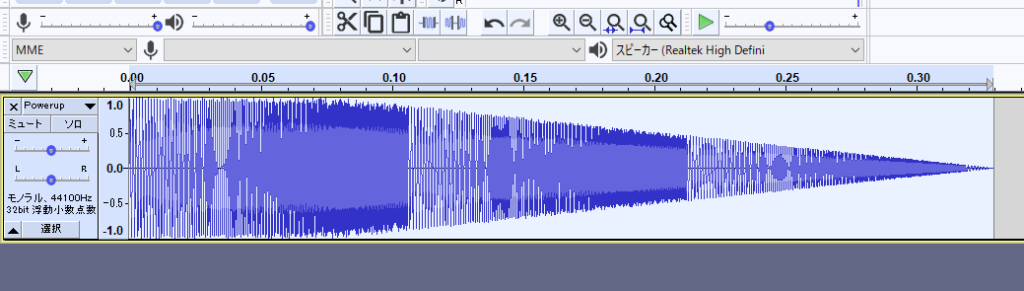
続けて「道具箱 > サンプルデータの書き出し」を選びます。
するとサンプルデータの書き出し画面が表示されます。
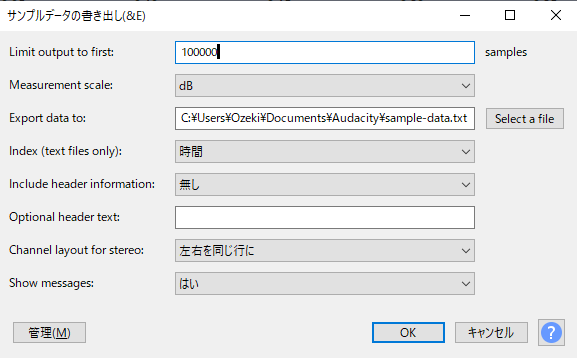
以下のように設定して「OK」ボタンで出力します。
- Limit output to first(出力するサンプル数の上限): 1000000 (100万。10万あたりだと2秒くらいになるため)
- Measurement scale: dB (音量)
- Export data to(書き出すテキストのパス): 任意のパス
- Index (text files only): 時間
- Include header information(ヘッダ情報を出力するかどうか): 無し
- Optional header text(ヘッダに出力する追加のテキスト): なし
- Channel layout for stereo: 左右を同じ行に
- Show messages(終了時のメッセージ表示): はい
すると、書き出し完了メッセージが表示されます
出力されたテキストを開いて、時間と音量(dB)がタブ区切りのテキストで出力されていることを確認します。
0.00000 -22.78476 0.00002 -16.76416 0.00005 -13.23990 0.00007 -10.73991 0.00009 -8.80098 0.00011 -7.21626 0.00014 -5.87602 0.00016 -4.71475 0.00018 -3.69099 0.00020 -2.77454 0.00023 -1.94563 0.00025 -1.18836 ・ ・ ・ 0.32973 -70.30900 0.32975 -73.40704 0.32977 -78.26780 0.32980 -90.30900 0.32982 -90.30900 0.32984 -80.76657 0.32986 -78.26780 0.32989 -78.26780 0.32991 -78.26780 0.32993 -78.26780 0.32995 -80.76657 0.32998 -84.28840
終端が 0.32998秒 なので、おおよそ 0.33秒であることがわかります。
ただこれをそのまま使うとかなり大きなデータとなるので、Pythonなどのスクリプト元を使ってデータを間引いても良いかもしれません。
以下は、0.1秒単位にするスクリプトの例です。
(※numpy を使用しています)
import numpy
f = open("sample-data.txt")
RANGE = 0.1 # 0.1秒単位の平均を求める
prev = 0
list = []
for line in f.read().split("\n"):
line = line.strip()
if line == "":
break
time, dB = line.split("\t")
time = float(time)
try:
dB = float(dB)
except ValueError:
dB = 0 # -ooなので無音
if time > prev + RANGE:
print("%3.2f: avg %3.2f"%(prev, numpy.mean(list)))
list = []
prev += RANGE
else:
list.append(dB)
#print(line)
実行結果
0.00: avg -8.73 0.01: avg -8.56 0.02: avg -8.83 0.03: avg -8.72 0.04: avg -8.60 0.05: avg -8.53 0.06: avg -8.65 0.07: avg -8.90 0.08: avg -8.88 0.09: avg -9.07 0.10: avg -9.64 0.11: avg -9.88 0.12: avg -10.28 0.13: avg -10.85 0.14: avg -11.23 0.15: avg -11.89 0.16: avg -12.33 0.17: avg -12.85 0.18: avg -13.54 0.19: avg -14.20 0.20: avg -14.71 0.21: avg -15.30 0.22: avg -16.30 0.23: avg -17.12 0.24: avg -17.88 0.25: avg -19.39 0.26: avg -20.58 0.27: avg -21.75 0.28: avg -23.75 0.29: avg -25.88 0.30: avg -28.56 0.31: avg -33.33
ただ、平均値だときれいな曲線にならないので、そのあたり気になる場合は フーリエ変換で圧縮するのが良いかもしれません
まとめて書き出す方法
複数ファイルをまとめて書き出すにはスクリプトを使用します。
スクリプトを使用するにはメニューから「編集 > 環境設定」を選びます。
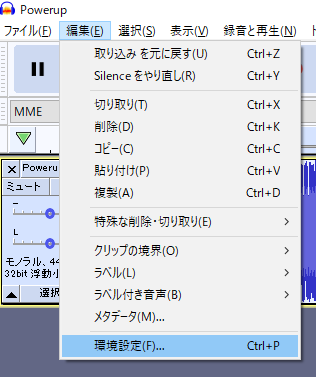
環境設定から「モジュール > mod-script-pipe」を「有効です」に設定します。
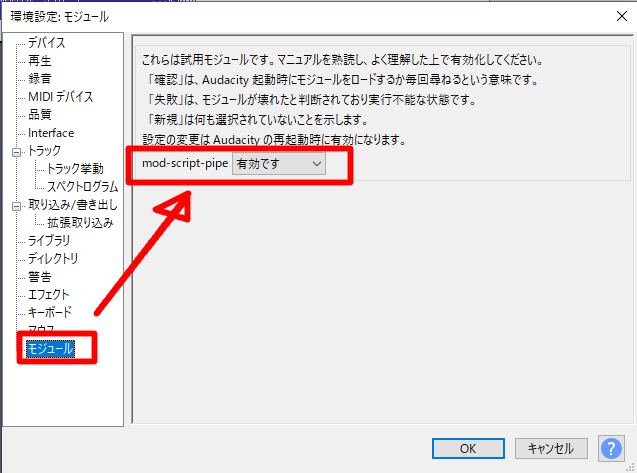
そうしたら、Audacity を再起動して設定を反映します
スクリプトの実装例
以下、Pythonスクリプトでの実装例です。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import sys
import glob
if sys.platform == 'win32':
TONAME = '\\\\.\\pipe\\ToSrvPipe'
FROMNAME = '\\\\.\\pipe\\FromSrvPipe'
EOL = '\r\n\0'
else:
TONAME = '/tmp/audacity_script_pipe.to.' + str(os.getuid())
FROMNAME = '/tmp/audacity_script_pipe.from.' + str(os.getuid())
EOL = '\n'
TOFILE = open(TONAME, 'w')
FROMFILE = open(FROMNAME, 'rt')
def send_command(command):
TOFILE.write(command + EOL)
TOFILE.flush()
def get_response():
result = ''
line = ''
while True:
result += line
line = FROMFILE.readline()
if line == '\n' and len(result) > 0:
break
return result
def do_command(command):
send_command(command)
response = get_response()
return response
# -------------------------------------------------
# ここからテキストを書き出す処理
# -------------------------------------------------
# 入力フォルダ
in_folder = "C:\\Users\\syun\\Desktop\\in\\"
# 対象ファイル
files = "*.wav"
files = glob.glob(in_folder + files)
for file in files:
print(file)
output = file.replace(".wav", ".txt")
# 入力ファイル
do_command('Import2: Filename="' + file + '"')
# 全選択する
do_command('SelectAll:')
# サンプルデータの出力
# number: 最大サンプル数
# filename: 出力ファイルのパス
# fileformat: インデックスの種類
# messages: メッセージの表示種別
do_command('SampleDataExport: number=1000000 filename="%s" fileformat=Time messages=Errors'%(output))
# トラックを閉じる
do_command('TrackClose:')
TOFILE.close()
FROMFILE.close()
このスクリプトは「C:/Users/syun/Desktop/in/」にある .wav ファイルからサンプルのテキストを書き出す処理となります
do_command() がAudacityコマンドの呼び出しですが、コマンドAPIのリファレンスは以下のページにあります